AM-DETR: 언어 쿼리를 사용한 오디오 순간 검색
본 논문에서는 텍스트 쿼리를 기반으로 긴 오디오에서 특정 순간을 예측하는 새로운 태스크인 오디오 순간 검색(AMR)을 제안합니다. 이를 위해 Clotho-Moment 데이터셋을 구축하고, 비디오 순간 검색에서 영감을 받아 오디오 특성 내의 시간적 의존성을 포착하는 DETR 기반 모델인 Audio Moment DETR (AM-DETR)을 제안하여 기존 클립 레벨 검색 방법을 능가하는 성능을 보입니다. 논문 제목: Language-based Audio Moment Retrieval
다음은 제공된 원문 마크다운 텍스트를 기반으로 작성된 논문 요약입니다.
논문 요약: AM-DETR: 언어 쿼리를 사용한 오디오 순간 검색
- 논문 링크: https://h-munakata.github.io/Language-based-Audio-Moment-Retrieval
- 저자: Hokuto Munakata, Taichi Nishimura, Shota Nakada, Tatsuya Komatsu (LY Corporation)
- 발표 시기: ICASSP 2025
- 주요 키워드: Audio Moment Retrieval, Language-based Audio Retrieval, DETR, Multimodal
1. 연구 배경 및 문제 정의
- 문제 정의: 기존 언어 기반 오디오 검색은 주로 짧은 오디오 클립(5~30초)에서 특정 오디오를 검색하는 데 초점을 맞췄습니다. 그러나 스포츠 중계 하이라이트 감지나 감시 시스템의 특정 순간 감지처럼, 편집되지 않은 긴 오디오에서 자연어 쿼리를 기반으로 특정 시간 구간(순간)을 정확히 찾아내는 새로운 수요가 발생했습니다.
- 기존 접근 방식: 기존 오디오 검색 모델을 긴 오디오에 적용하는 간단한 방법은 긴 오디오를 여러 짧은 클립으로 나누고, 각 클립에 대해 텍스트 쿼리와의 유사도를 계산하는 것입니다. 하지만 이 방식은 클립 간의 시간적 의존성을 포착하지 못하고 각 클립을 독립적으로 처리하여 최적의 성능을 내기 어렵다는 한계가 있습니다.
2. 주요 기여 및 제안 방법
- 논문의 주요 기여:
- 언어 쿼리를 사용하여 긴 오디오에서 특정 순간을 예측하는 새로운 태스크인 오디오 순간 검색(Audio Moment Retrieval, AMR)을 제안하고 정의했습니다.
- AMR 태스크를 위한 대규모 시뮬레이션 데이터셋인 Clotho-Moment를 구축하여 공개했습니다.
- 비디오 순간 검색(VMR)에서 영감을 받아 오디오 특징 내의 시간적 의존성을 효과적으로 포착하는 DETR(DEtection TRansformer) 기반 모델인 Audio Moment DETR (AM-DETR)을 제안했습니다.
- 실제 데이터에 대한 제안 방법의 효과와 견고성을 측정하기 위해 수동으로 주석을 단 소규모 데이터셋을 제공했습니다.
- 제안 방법:
AM-DETR은 VMR 모델(특히 QD-DETR)에서 영감을 받아 오디오와 텍스트 간의 교차 모달 의존성 및 오디오 특징 내의 시간적 의존성을 모두 포착하도록 설계되었습니다.
- 특징 추출기: 입력 오디오와 텍스트 쿼리를 임베딩으로 변환합니다. 긴 오디오의 경우, 사전 훈련된 오디오 인코더(CLAP, VR)가 짧은 클립 단위로 임베딩을 추출한 후 시간 축을 따라 풀링하여 사용합니다.
- DETR 기반 네트워크:
- Cross-attention Transformer: 오디오 임베딩과 텍스트 임베딩 간의 유사도를 측정하여 교차 모달 의존성을 포착합니다.
- Transformer Encoder: Self-attention 메커니즘을 통해 잠재 특징 간의 시간적 의존성을 포착합니다.
- Transformer Decoder: 인코더의 출력을 바탕으로 개의 후보 오디오 모멘트(시작 및 종료 시간)와 각 모멘트의 신뢰도 점수를 예측합니다.
- 손실 함수: 예측된 모멘트의 정확도를 위한 모멘트 손실( 손실, gIoU 손실)과 신뢰도 점수 예측을 위한 점수 손실(교차 엔트로피 손실)로 구성됩니다. 최적의 매칭 손실을 통해 예측된 모멘트와 실제 모멘트 간의 대응 관계를 결정하여 학습을 진행합니다.
3. 실험 결과
- 데이터셋:
- 훈련: Clotho-Moment (Clotho 및 WalkingTour 데이터셋을 오버레이하여 생성된 대규모 시뮬레이션 AMR 데이터셋).
- 평가: Clotho-Moment 평가 스플릿, UnAV-100 서브셋 (수동 주석이 달린 소규모 실제 오디오 데이터셋), TUT Sound Events 2017 (제로샷 사운드 이벤트 탐지(SED) 성능 평가용).
- 주요 결과:
- AM-DETR vs. 베이스라인: AM-DETR은 모든 지표에서 기존 슬라이딩 윈도우 기반의 클립 수준 오디오 검색 베이스라인 모델보다 월등히 뛰어난 성능을 보였습니다. 특히, UnAV-100 서브셋에서 Recall1@0.7은 9.00 포인트, 평균 mAP는 11.82 포인트 향상되었습니다. 이는 오디오 특징 간의 시간적 의존성을 포착하는 것이 AMR에 매우 중요함을 시사합니다.
- 특징 추출기의 영향: 대조 학습(contrastive learning)을 통해 사전 훈련된 특징 추출기(CLAP, VR)를 사용하는 것이 검색 성능을 크게 향상시켰습니다.
- 윈도우 길이: 오디오 인코더의 윈도우 길이는 짧을수록 AM-DETR의 성능에 더 유리했습니다. 이는 베이스라인 모델의 결과와 대조되는 흥미로운 결과입니다.
- 훈련 데이터 양: 시뮬레이션된 훈련 데이터의 양이 많을수록 성능이 향상되었으며, 데이터 양 증가에 따른 추가적인 개선 가능성을 보여주었습니다.
- 제로샷 SED: AMR 모델은 제로샷 조건에서도 지도 학습 기반의 기존 SED 모델 F1 점수의 77% 이상을 달성했으며, 임계값에 덜 민감한 특성을 보였습니다.
4. 개인적인 생각 및 응용 가능성
- 장점:
- 기존 오디오 검색의 한계(짧은 클립 중심)를 명확히 지적하고, 긴 오디오 내의 특정 순간을 검색하는 새로운 태스크를 정의하여 연구의 새로운 방향을 제시했습니다.
- 비디오 도메인에서 성공적으로 검증된 DETR 아키텍처를 오디오 도메인에 효과적으로 적용하여, 시간적 의존성 모델링의 중요성을 입증했습니다.
- 대규모 시뮬레이션 데이터셋(Clotho-Moment)을 구축하여 데이터 부족 문제를 해결하고, 실제 데이터셋으로 모델의 견고성을 검증한 점이 인상 깊습니다.
- AMR 모델이 제로샷 사운드 이벤트 탐지(SED)에도 활용될 수 있음을 보여주어, 모델의 다재다능한 응용 가능성을 확장했습니다.
- 단점/한계:
- Clotho-Moment 데이터셋이 시뮬레이션 기반이므로, 실제 오디오 환경의 복잡성(예: 여러 이벤트의 동시 발생, 겹치는 순간 등)을 완전히 반영하지 못할 수 있습니다 (현재는 쿼리당 단일 모멘트만 생성).
- 수동 주석 데이터셋(UnAV-100)의 규모가 아직 작아, 실제 환경에서의 모델 일반화 성능을 더 광범위하게 검증하기 위한 추가적인 대규모 데이터셋 구축이 필요합니다.
- DETR 기반 모델의 특성상 계산 비용이 높을 수 있으며, 실시간 응용을 위한 최적화가 필요할 수 있습니다.
- 응용 가능성:
- 미디어 콘텐츠 분석: 스포츠 중계, 뉴스, 팟캐스트 등에서 특정 이벤트(예: 골, 박수, 특정 발언)가 발생하는 순간을 자동으로 찾아 하이라이트를 생성하거나 콘텐츠를 요약하는 데 활용될 수 있습니다.
- 보안 및 감시: CCTV 오디오에서 비명, 총성, 유리 깨지는 소리 등 특정 위험 상황의 순간을 자동으로 감지하여 신속한 대응을 돕는 시스템에 적용될 수 있습니다.
- 오디오 아카이브 관리: 방대한 오디오 라이브러리에서 자연어 쿼리를 통해 원하는 사운드 이펙트나 특정 장면을 효율적으로 검색하는 데 사용될 수 있습니다.
- 음악 및 오디오 편집: 특정 악기 소리, 보컬 구간, 또는 분위기 변화가 발생하는 순간을 정확히 찾아내어 오디오 편집 작업을 자동화하거나 효율화할 수 있습니다.
5. 추가 참고 자료
- 논문 프로젝트 페이지 (데이터셋 및 코드 포함): https://h-munakata.github.io/Language-based-Audio-Moment-Retrieval
- Lighthouse 오픈소스 라이브러리: https://github.com/line/lighthouse
Munakata, Hokuto, et al. "Language-based audio moment retrieval." ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025.
Language-based Audio Moment Retrieval
Hokuto Munakata<br>LY Corporation<br>hokuto.munakata@lycorp.co.jp
Taichi Nishimura<br>LY Corporation<br>tainishi@lycorp.co.jp
Shota Nakada<br>LY Corporation<br>shota.nakada@lycorp.co.jp
Tatsuya Komatsu<br>LY Corporation<br>tatsuya.komatsu@lycorp.co.jp
Abstract
이 논문에서는 AMR(audio moment retrieval)이라는 새로운 태스크를 제안하고 설계합니다. 오디오 데이터베이스에서 짧은 오디오 클립을 검색하는 기존의 언어 기반 오디오 검색 태스크와 달리, AMR은 텍스트 쿼리를 기반으로 편집되지 않은 긴 오디오에서 관련 순간을 예측하는 것을 목표로 합니다. AMR에 대한 이전 연구가 부족하기 때문에, 우리는 먼저 Clotho-Moment라는 전용 데이터셋을 구축했으며, 이는 모멘트 주석이 달린 대규모 시뮬레이션 오디오 녹음으로 구성됩니다. 그런 다음 AMR 태스크의 기본 프레임워크로서 Audio Moment DETR(AM-DETR)이라는 DETR 기반 모델을 제안합니다. 이 모델은 유사한 비디오 모멘트 검색 태스크에서 영감을 받아 오디오 특징 내의 시간적 의존성을 포착함으로써 기존의 클립 수준 오디오 검색 방법을 능가합니다. 또한, 실제 데이터에 대한 우리 방법의 효과와 견고성을 적절히 측정하기 위해 수동으로 주석을 단 데이터셋을 제공합니다. 실험 결과, Clotho-Moment로 훈련된 AM-DETR은 모든 지표에서 슬라이딩 윈도우를 사용한 클립 수준 오디오 검색 방법을 적용한 기준 모델보다 성능이 우수했으며, 특히 Recall1@ 0.7을 9.00 포인트 향상시켰습니다. 우리의 데이터셋과 코드는 https://h-munakata.github.io/Language-based-Audio-Moment-Retrieval 에서 공개적으로 사용할 수 있습니다.
Index Terms-Language-based audio moment retrieval, Audio retrieval, Clotho-Moment, Audio Moment DETR
I. Introduction
언어 기반 오디오 검색(단순히 오디오 검색이라고도 함)은 자연어 쿼리를 사용하여 오디오 데이터베이스에서 원하는 오디오를 검색하는 것입니다. 연구자들은 이 기술이 역사적 사운드 아카이브나 음향 효과의 검색 시스템과 같은 광범위한 응용 분야를 가지고 있기 때문에 주목하고 있습니다 [1]. 대규모 오디오-텍스트 데이터셋 [2]-[4]의 도입으로 다양한 접근 방식이 제안되었습니다 [5]-[9].
이전 연구들은 짧은 오디오(5초에서 30초)로 구성된 오디오-텍스트 데이터셋을 사용했기 때문에, 자연어로부터 짧은 오디오를 검색하는 방법을 제안했습니다. 비전 도메인에서의 교차 모달 검색 [10]에서 영감을 받아, 주류 접근 방식은 오디오-텍스트 쌍을 이용한 대조 학습(contrastive learning)을 사용하는 것입니다 [5]-[9]. 이 모델은 오디오 클립과 텍스트 쿼리를 공유 임베딩 공간으로 매핑하고, 텍스트 쿼리와 데이터베이스 내 오디오의 임베딩 간의 유사도를 계산하여 관련 오디오를 검색합니다.
기존 오디오 검색 모델은 오디오가 짧은 클립으로 잘려 있다고 가정하지만, 편집되지 않은 긴 오디오에서 특정 시간 구간을 검색해야 하는 수요가 많습니다. 잠재적인 응용 분야로는 스포츠 중계의 하이라이트 순간 감지나 감시 시스템의 범죄 순간 감지 등이 있습니다. 이러한 응용은 자연어 쿼리를 사용하여 오디오 내의 순간을 검색하도록 동기를 부여합니다. 그림 1은 우리가 구현하고자 하는 검색 시스템을 보여줍니다. "관중들이 스포츠를 보며 환호한다"는 쿼리와 긴 오디오가 주어지면, 모델은 시작 및 종료 타임스탬프(16초에서 44초)로 오디오 순간을 검색할 것으로 기대됩니다. 이러한 모멘트 리트리버를 구축하기 위한 간단한 해결책은 기존 오디오 검색 방법을 세 단계로 활용하는 것입니다: 긴 오디오를 여러 클립으로 나누고, 이를 오디오 검색 모델로 전달한 다음, 공유 임베딩 공간에서 텍스트 쿼리와 오디오 클립 임베딩 간의 유사도를 계산하는 것입니다. 그러나 이 접근 방식은 오디오 클립 시퀀스를 독립적으로 처리하여 클립 간의 시간적 의존성을 포착하지 못하기 때문에 차선책입니다.
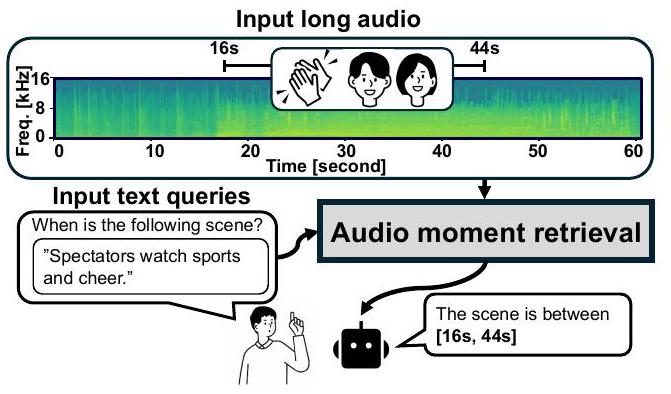
Fig. 1. An overview of audio moment retrieval (AMR). Given a long audio and text query, the system retrieves the relevant moments as the start and end time stamps.
이 한계를 해결하기 위해, 우리는 시간적 의존성 모델링이 잘 연구된 비디오 도메인 분야에서 영감을 얻을 수 있습니다. 비디오 모멘트 검색(VMR)은 긴 비디오에서 특정 순간을 검색하는 유사한 태스크입니다 [11]-[19]. 이 태스크에서는 DEtection TRansformer(DETR) 기반 모델 [20]이 높은 검색 성능을 보여줍니다 [15], [17], [18]. 이 모델들은 비디오 프레임 내의 시간적 의존성뿐만 아니라 프레임과 텍스트 쿼리 간의 교차 모달 유사성도 학습하여 정확한 순간 예측을 가능하게 합니다. VMR에서는 다양한 방법이 제안되었으며, 우리는 이러한 방법들의 아이디어가 우리의 목표 시스템에 도움이 될 것이라고 생각합니다.
본 논문에서는 VMR에서 볼 수 있는 방법론과 성공 사례에서 영감을 받아 오디오 모멘트 검색(AMR)이라는 새로운 태스크를 제안하고 설계합니다. AMR에 대한 선행 연구가 부족한 점을 고려하여, 먼저 AMR 전용 데이터셋인 Clotho-Moment를 구축했습니다. 이 데이터셋은 모멘트 주석이 달린 대규모 시뮬레이션 오디오 녹음으로 구성되어 있습니다. 그런 다음, 기존의 오디오 클립 검색을 넘어서는 AMR 태스크의 기본 프레임워크로서 Audio Moment DETR이라는 DETR 기반 AMR 모델을 제안합니다. 또한, 실제 데이터에서 제안된 방법들의 효과와 견고성을 제대로 측정할 수 있도록 수동으로 주석을 단 데이터셋을 제공합니다. 우리의 연구가 오디오 검색의 새로운 방향을 제시하고 이 분야의 미래 연구를 위한 길을 열어주기를 바랍니다.
II. Difference to Existing Tasks
AMR은 오디오 및 비전 도메인에서 세 가지 유사한 태스크를 가집니다: 사운드 이벤트 탐지(SED), 타겟 소스 추출(TSE), 비디오 모멘트 검색(VMR). 이 섹션에서는 AMR과 이들 태스크 간의 차이점을 열거함으로써 AMR의 독창성을 강조합니다. 사운드 이벤트 탐지(SED)는 입력 오디오로부터 사운드 이벤트 클래스 레이블과 이벤트 시간 경계를 모두 예측하는 태스크입니다 [21]-[26]. SED는 타겟 레이블이 미리 정해져 있고 각 레이블이 단일 이벤트에 해당한다고 가정합니다. 반면, AMR은 쿼리에 대해 개방형 어휘(open vocabulary)를 가정하므로 여러 이벤트와 관련된 쿼리를 처리할 수 있습니다. 따라서 AMR은 개방형 어휘 환경에서의 제로샷(zero-shot) SED로 볼 수 있습니다. 실제로, 우리는 AMR 모델을 사용하여 제로샷 SED를 실험했습니다(섹션 V-C).
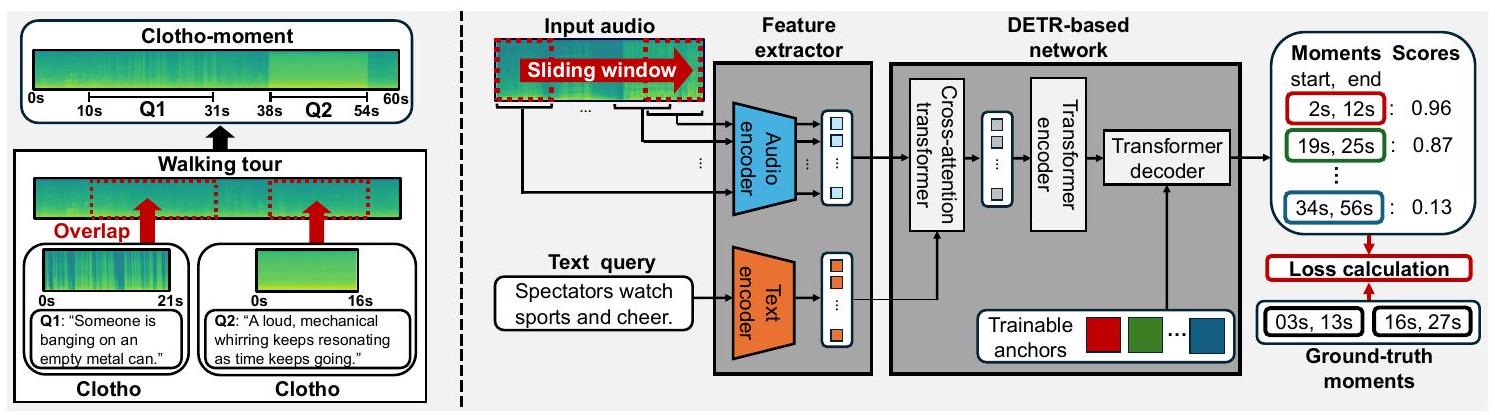
Fig. 2. The left figure describes Clotho-Moment. By overlaying Clotho on Walking Tour, audio and text query-audio moment pairs are generated. The right side of the figure describes the architecture of the proposed Audio Moment DETR. This model first extracts embedding by audio/text encoder and then the DETR-based network transforms the embedding to pairs of the audio moment and its confidence score.
타겟 소스 추출(TSE)은 입력 혼합물에서 텍스트 쿼리와 관련된 소스를 추출하는 태스크입니다 [27], [28]. AMR과 TSE의 차이점은 타겟 출력에 있습니다. AMR은 관련 순간을 식별하는 것을 목표로 하는 반면, TSE는 관련된 분리된 소스 신호를 추출하는 것을 목표로 합니다. 따라서 TSE로 분리된 신호를 얻더라도 원하는 순간을 검색하기 위해서는 여전히 AMR을 수행해야 합니다. 비디오 모멘트 검색(VMR)은 VMR이 오디오 대신 시각 데이터에 초점을 맞춘다는 점을 제외하면 입력과 출력이 AMR과 동일한 태스크입니다 [11], [12], [14], [15], [17]-[19]. 비디오에서 추출한 오디오 특징을 활용하는 VMR 모델이 있지만 [19], 오디오 특징은 비디오 프레임에 대한 보조 정보로만 사용됩니다.
III. Dataset for Audio Moment Retrieval
우리는 편집되지 않은 오디오 데이터에서 텍스트 쿼리와 관련된 오디오 순간을 검색하기 위한 데이터셋을 구축합니다. AMR에 대해 우리가 가정하는 오디오는 1분 길이이며, 골이 들어가고 사람들이 환호하는 장면을 포함하는 스포츠 방송의 오디오와 같이 텍스트로 표현될 수 있는 특정 장면들을 포함합니다. 이러한 가정을 바탕으로 우리는 두 가지 유형의 데이터셋을 만듭니다.
A. Clotho-Moment
우리는 대규모 시뮬레이션 AMR 데이터셋인 Clotho-Moment를 제안합니다. 이 데이터셋은 기존의 오디오-텍스트 데이터를 활용한 시뮬레이션을 기반으로 생성되며, 추가적인 주석 작업이 필요하지 않습니다. 우리는 이 데이터셋을 Clotho [2]와 WalkingTour [29]라는 두 데이터셋으로부터 생성했습니다. Clotho는 Freesound에서 수집된 다양한 수동 주석 1530초 오디오 클립 데이터로 구성됩니다. 각 오디오 샘플에는 820 단어로 구성된 5개의 캡션이 있습니다. 이 데이터셋은 개발, 검증, 평가 스플릿으로 나뉘며 각 스플릿에는 3839, 1045, 1045개의 오디오 샘플이 포함됩니다. Walking Tour는 다양한 도시에서 녹화된 1시간 이상의 비디오 10개를 포함합니다. 우리는 비디오의 오디오만 사용합니다. Clotho를 따라, 우리는 이 데이터셋을 7:1:2 비율로 개발, 검증, 평가 스플릿으로 나눕니다.
Clotho-Moment는 Clotho에 포함된 일부 장면을 포함하여 도시에서 녹음된 긴 오디오를 시뮬레이션합니다. 그림 2의 왼쪽에 표시된 것처럼, 이 데이터셋은 Clotho와 Walking tour 오디오 샘플을 각각 전경과 배경으로 사용하여 생성됩니다. 스피커 분할을 위해 제안된 시뮬레이션 방법 [30]에서 영감을 받아, 오디오와 텍스트 쿼리 및 모멘트 쌍은 알고리즘 1에 표시된 것처럼 무작위로 샘플링된 간격으로 Walking Tour 샘플에 Clotho 샘플을 오버레이하여 생성됩니다. 우리 방법은 쿼리당 단일 오디오 모멘트만 생성할 수 있으며 각 장면은 겹치지 않습니다.
데이터를 더 현실적으로 만들기 위해 몇 가지 조정을 합니다. 다양한 볼륨 레벨의 장면을 시뮬레이션하기 위해, 샘플링된 Clotho 및 Walking Tour 오디오의 신호 전력은 각각 와 에서 무작위로 가중됩니다. 오디오 모멘트를 더 정확하게 만들기 위해, 전체 신호 전력보다 20 dB 낮은 Clotho 클립의 무음 시작과 끝 부분을 제거했습니다. 평균 간격 길이를 제어하는 하이퍼파라미터 를 30초로 설정했습니다. 아래에 설명된 수동 주석 데이터셋과의 불일치를 줄이기 위해, Walking Tour 샘플은 사전에 1초 간격으로 1분 세그먼트로 분할됩니다. 최종적으로 개발, 검증, 평가 스플릿에 대해 각각 32694, 4918, 6649개의 샘플을 생성했습니다.
<코드> Algorithm 1 Generating Clotho-Moment Input: (\mathcal{D}{\text {Clotho }} \quad / /) Set of of query-foreground audio pairs (\mathcal{D}{\text {WalkingTour }} \quad / /) Set of background audio Output: (\mathbf{x} \quad / /) Generated audio (Y=\left{\left(q_{1}, t_{1, \text { start }}, t_{1, \text { end }}\right), \ldots\right} \quad / /) Set of query-moment pairs (Y \leftarrow \emptyset, t=0 \quad / /) Initialize (\mathbf{x} \sim \mathcal{D}{\text {WalkingTour }} \quad / /) Sample background audio while do (d \sim \frac{1}{\beta} \exp \left(-\frac{d}{\beta}\right) \quad / /) Sample interval (\mathbf{x}{\text {moment }}, q \sim \mathcal{D}{\text {Clotho }} \quad / /) Sample foreground audio and its query (t{\text {start }} \leftarrow t+d) (t_{\text {end }} \leftarrow t_{\text {start }}+) duration (\left(\mathbf{x}{\text {moment }}\right)) if (t{\text {end }}>) duration( (\mathbf{x}) ) then break end if (\mathbf{x}\left[t_{\text {start }}: t_{\text {end }}\right]=\mathbf{x}\left[t_{\text {start }}: t_{\text {end }}\right]+\mathbf{x}{\text {moment }} \quad / /) Overlay (Y \leftarrow Y \mid\left{\left(q, t{\text {start }}, t_{\text {end }}\right)\right} \quad / /) Update sets (t \leftarrow t_{\text {end }}) end while return (\mathbf{x}, Y) </코드>
B. Real Data for Evaluation
시뮬레이션 데이터 외에도, 우리는 더 현실적인 환경에서 검색 성능을 평가하기 위해 소규모의 수동 주석 AMR 데이터셋을 만듭니다. 다양한 장면을 포함하는 비교적 긴 비디오 데이터 컬렉션으로, 우리는 편집되지 않은 YouTube 비디오 데이터셋인 UnAV-100 [31]을 선택하고 비디오에서 오디오를 추출했습니다. 우리는 77개의 비디오를 선택하고 100개의 새로운 텍스트 쿼리와 오디오 모멘트를 주석 처리했습니다. 평가를 쉽게 하기 위해 각 쿼리는 단일 오디오 모멘트에 해당합니다. 오디오 길이는 45초에서 60초이며 모멘트의 해상도는 1초입니다. 캡션은 평균 6.3 단어로 구성됩니다.
IV. Audio moment retrieval
이 섹션에서는 오디오 모멘트 검색(AMR)을 정의합니다. AMR을 다루기 위해, 우리는 VMR 모델 [15], [17], [18]에서 영감을 받은 Audio Moment DETR(AM-DETR)을 제안합니다. Clotho-Moment로 훈련함으로써, AM-DETR은 오디오 특징 내의 시간적 의존성과 오디오 특징과 텍스트 쿼리 간의 교차 모달 유사성을 모두 포착할 수 있습니다.
A. Task Formulation
우리는 오디오 모멘트 검색을 주어진 텍스트 쿼리에 해당하는 오디오 모멘트를 예측하는 태스크로 정의합니다. 입력 오디오를 로, 텍스트 쿼리를 로, 출력 오디오 모멘트를 로 나타냅니다. 여기서 는 쿼리와 관련된 오디오 모멘트를 나타내며 여러 모멘트로 구성될 수 있습니다: . 각 모멘트는 시작 시간과 종료 시간의 튜플, 로 표현됩니다. 이 태스크는 입력 오디오 와 텍스트 쿼리 가 주어졌을 때 관련 오디오 모멘트 를 찾는 매핑 문제로 볼 수 있습니다. 공식적으로, 이는 로 표현될 수 있습니다. 핵심 과제는 함수 을 어떻게 모델링하는가입니다.
B. Audio Moment DETR
우리는 VMR을 위해 제안된 모델 [15], [17], [18]에서 영감을 받은 AMR 모델인 Audio Moment DETR(AM-DETR)을 제안합니다. 그림 2의 오른쪽에 표시된 것처럼, AM-DETR은 VMR 모델과 동일하게 특징 추출기와 DETR 기반 네트워크로 구성됩니다. AM-DETR의 핵심 부분은 오디오 특징 간의 시간적 의존성을 포착하는 DETR 기반 네트워크 [15], [17], [18]입니다. 구체적으로, AM-DETR의 아키텍처는 QD-DETR을 기반으로 하며, 이는 간단하지만 비디오 프레임 간의 시간적 의존성과 프레임과 텍스트 쿼리 간의 교차 모달 의존성을 모두 포착하여 VMR에 대해 높은 검색 성능을 달성합니다 [17]. (1) Feature extractor. 특징 추출기는 오디오/텍스트 인코더로 구성됩니다. 입력 오디오 와 텍스트 쿼리 가 주어지면, 각 인코더는 이를 다음과 같이 임베딩으로 변환합니다:
여기서 와 는 각각 길이가 와 인 차원 언어 및 음향 임베딩을 나타냅니다. 이어지는 DETR 기반 네트워크가 오디오와 텍스트 임베딩 간의 유사성을 포착하도록 유도하기 위해, 우리는 대조 학습(contrastive learning)에 기반한 사전 훈련된 오디오/텍스트 인코더를 사용합니다. 오디오 인코더는 대조 학습을 통해 짧은 클립으로만 훈련되었기 때문에 긴 오디오와 텍스트의 임베딩 간의 유사성을 정확하게 측정할 수 없습니다. 이 문제를 해결하기 위해, 우리는 를 슬라이딩 윈도우를 사용하여 개의 짧은 클립 으로 미리 나눕니다. 우리는 짧은 클립을 인코딩하고 시간 축을 따라 독립적으로 임베딩을 풀링합니다:
실험에서 슬라이딩 윈도우의 홉 길이는 1로 설정했습니다. (2) DETR-based network. 먼저, 이 네트워크는 와 를 Cross-attention Transformer를 통해 오디오와 텍스트 임베딩 간의 유사도를 측정하여 교차 모달 의존성을 포착하는 순차적 잠재 특징으로 변환합니다:
또한, 잠재 특징 간의 시간적 의존성을 포착하기 위해, Transformer 인코더는 self-attention 메커니즘을 활용하여 를 변환합니다:
마지막으로, Transformer 디코더는 을 개의 후보 오디오 모멘트 와 그 신뢰도 점수 로 변환합니다. 신뢰도 점수는 해당 예측된 모멘트가 얼마나 타당한지를 나타냅니다. 여기서 는 실제 모멘트의 수보다 충분히 크다고 가정하는 출력 수를 제어하는 하이퍼파라미터입니다. 개의 후보를 출력하기 위해, 디코더는 외에 개의 학습 가능한 앵커를 입력으로 받습니다. 최종적으로 디코더는 다음과 같이 공식화됩니다:
여기서 와 는 각각 예측된 모멘트와 신뢰도 점수의 튜플입니다. 모멘트는 모델이 객체 탐지를 모방하도록 구현되었기 때문에 오디오 길이에 대한 상대적인 중심과 너비로 출력됩니다. 실제 오디오 모멘트의 수 은 알 수 없으므로, 우리는 신뢰도 점수를 임계값과 비교하여 개의 후보 중에서 타당한 오디오 모멘트를 선택합니다. (3) Loss function. 정확한 오디오 모멘트와 신뢰도 점수를 출력하기 위해, AM-DETR은 모멘트 손실 와 점수 손실 라는 두 가지 유형의 손실을 최소화하도록 훈련됩니다. 모멘트 손실은 손실과 일반화된 Intersection over Union(gIoU) 손실 [32]로 구성됩니다. 손실은 예측된 오디오 모멘트의 중심 좌표와 너비의 오차를 다음과 같이 측정합니다:
여기서 첫 번째 항과 두 번째 항은 각각 중심 좌표와 너비의 오차를 나타냅니다. gIoU 손실 는 와 사이의 IoU의 음수 값을 나타내며 IoU에 대한 직접적인 최적화를 위해 사용됩니다. 최종적으로, 모멘트 손실은 이들 손실의 가중 합으로 얻어집니다:
신뢰도 점수를 정확하게 예측하기 위해, 모델은 각 출력 후보가 해당하는 실제 값이 있는지 여부를 교차 엔트로피 손실을 사용하여 식별하도록 학습합니다. 여기서 우리는 개의 출력 후보에 대해 새로운 인덱스 를 도입하고, -번째 후보가 해당하는 실제 값을 갖는다고 가정합니다. 이 가정 하에, 점수 손실은 다음과 같이 얻어집니다:
여기서 첫 번째 항은 해당하는 실제 값이 있는 모멘트의 신뢰도 점수를 높이는 역할을 하고, 두 번째 항은 해당하는 실제 값이 없는 모멘트의 점수를 낮추는 역할을 합니다.
개의 후보와 개의 실제 값 사이의 정확한 대응 관계를 알 수 없으므로, 우리는 다음 매칭 손실을 최소화하는 최적의 대응 관계를 결정합니다:
여기서는 경험적으로 식 (9)에서 가 아닌 를 사용하는 것이 성능을 향상시키는 것으로 알려져 있습니다 [20]. 우리는 최적의 인덱스를 로 표기하며, 여기서 는 모든 순열의 집합입니다. 최종적으로 전체 손실은 모멘트 손실과 CE 손실의 가중 합으로 얻어집니다:
V. Experiment
우리는 ClothoMoment로 훈련된 제안된 AMR 모델과 베이스라인을 평가했습니다. 우리의 실험은 Lighthouse 1 [33]이라는 오픈소스 라이브러리를 사용하여 수행되었으며, 데이터셋도 공개적으로 이용 가능합니다.
1TABLE I RETRIEVAL PERFORMANCE ON EACH DATASET. FOR ALL METRICS, HIGHER IS BETTER.
| Method | Feature extractor | Win len | Clotho-Moment (eval) | R1 | TUT-Sound Event 2017 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | mAP | R1 | mAP | ||||||||||||||
| @ 0.5 | @ 0.7 | @0.5 | @0.75 | avg | @0.5 | @ 0.7 | @0.5 | @ 0.75 | avg | @ 0.5 | @0.7 | @0.5 | @ 0.75 | avg | |||
| Baseline | CLAP | 1.0 | 20.92 | 14.65 | 22.12 | 13.56 | 13.61 | 18.00 | 5.00 | 19.50 | 6.00 | 7.45 | 4.81 | 1.92 | 3.85 | 0.96 | 1.59 |
| Baseline | CLAP | 4.0 | 44.79 | 30.89 | 46.83 | 28.08 | 27.19 | 53.00 | 24.00 | 55.00 | 23.00 | 25.30 | 4.81 | 0.96 | 4.73 | 1.48 | 1.93 |
| Baseline | CLAP | 7.0 | 62.11 | 48.05 | 62.87 | 41.99 | 38.11 | 55.00 | 32.00 | 57.00 | 24.50 | 29.00 | 7.69 | 3.85 | 7.39 | 1.68 | 3.07 |
| AM-DETR | VR w/o CL | 1.0 | 49.90 | 30.98 | 65.19 | 28.42 | 32.92 | 28.00 | 12.00 | 43.05 | 12.14 | 17.71 | 6.73 | 3.85 | 11.63 | 2.22 | 4.42 |
| AM-DETR | VR | 1.0 | 88.25 | 82.66 | 91.21 | 82.01 | 77.09 | 58.00 | 41.00 | 64.31 | 41.06 | 40.82 | 15.38 | 6.73 | 15.06 | 4.09 | 5.55 |
| AM-DETR | CLAP | 1.0 | 87.50 | 81.86 | 91.39 | 82.51 | 76.66 | 61.00 | 39.00 | 67.08 | 36.42 | 40.39 | 14.42 | 5.77 | 15.72 | 4.38 | 6.23 |
A. Model Configuration
Proposed model. 우리는 Clotho-Moment를 사용하여 AM-DETR을 훈련시켰습니다. 특징 추출기의 영향을 조사하기 위해, CLAP [5], VR, 그리고 대조 학습이 없는 VR의 세 가지 특징 추출기를 사용했습니다. 여기서 VR은 VAST [34]와 RoBERTa [35]로 구성된 오디오 검색 모델로, 우리의 대규모 데이터셋으로 훈련되었으며 Clotho 벤치마크에서 CLAP을 크게 능가합니다 [36]. 비교를 위해, 우리는 1, 4, 7초 윈도우 길이를 가진 슬라이딩 윈도우를 사용했습니다. DETR 기반 네트워크의 하이퍼파라미터 설정은 [17]을 따랐습니다. Transformer 인코더와 디코더 모두 256개 유닛과 8개 헤드를 가진 2개의 어텐션 레이어 스택으로 구성되었으며, 피드-포워드 레이어의 차원은 1024로 설정되었습니다. AdamW 옵티마이저 |37|를 학습률 로 사용했으며, 배치 크기 32로 100 에포크 동안 모델을 훈련했습니다. Baseline. 베이스라인으로는 기존 오디오 검색 모델과 슬라이딩 윈도우를 결합한 모델을 사용했습니다. 오디오 모멘트를 얻기 위해, 베이스라인은 각 윈도우 프레임에 대해 오디오와 텍스트 임베딩 간의 유사도를 측정하고, 이를 임계값과 비교하여 이진화합니다. 신뢰도 점수는 모멘트 내의 평균 유사도로 정의됩니다. 성능 향상을 위해, 결과로 나온 이진 시퀀스에 중간값 필터를 적용했습니다. 이진화를 위한 임계값과 중간값 필터의 길이는 Clotho-Moment의 검증 스플릿으로 조정되었습니다.
B. Evaluation
우리는 VMR 15|에서 널리 사용되는 지표인 Recall1 (R1)과 mean average precision (mAP)을 측정했습니다. 두 지표 모두 실제 값과 예측된 모멘트 간의 IoU가 임계값 를 초과하는지 여부를 기반으로 합니다. R1은 가장 높은 신뢰도 점수를 가진 후보를 사용하여 단일 오디오 모멘트를 평가하는 지표입니다. 반면, mAP는 모든 실제 값과 해당 후보를 고려하여 여러 오디오 모멘트를 평가하는 지표입니다. 또한 0.5에서 0.95까지 0.05 간격으로 여러 에 대한 평균 mAP도 측정합니다.
평가를 위해 Clotho-Moment 평가 스플릿, UnAV-100 서브셋을 사용했습니다. 이 외에도 참고용으로 SED에서 사용되는 TUT sound events 2017(TUT) |38|도 사용했습니다. TUT의 레이블은 AMR의 텍스트 쿼리로 사용하기에는 너무 짧은 단어로 구성되어 있어, 각 레이블에 평균 4.8 단어의 프롬프트를 추가했습니다.
C. Results
Proposed vs Baseline. 표 I (행 3과 6)에서 볼 수 있듯이 AM-DETR은 모든 지표에서 베이스라인을 크게 능가했습니다. 특히, UnAV-100 서브셋에 대한 R1@0.7 및 평균 mAP의 향상은 각각 9.00 및 11.82 포인트였습니다. 이 결과는 오디오 특징 간의 시간적 의존성을 포착하는 것이 AMR에 중요하다는 것을 시사합니다. Feature extractor. 특징 추출기에서 대조 학습의 영향을 조사했습니다. 먼저, 특징 추출기의 대조 학습이 검색 성능을 크게 향상시킨다는 것을 발견했습니다(행 4와 5). 특히, UnAV-100 서브셋에 대한 R1@ 0.7 및 평균

Fig. 3. Comparative study for the window length and the amount of data. The vertical axes for both figures represent average mAP on UnAV-100 subset.
TABLE II Frame-level classification performance on TUT. All metrics ARE MEASURED IN MICRO AVERAGE. THE WINDOW LENGTHS OF SED-CLAP AND AM-DETR WERE 7 AND 1, RESPECTIVELY.
| Method | Zero-shot | Tune | Thr. | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| SED-CLAP | - | 0.50 | 47.07 | 12.19 | 19.37 | |
| SED-CLAP | 0.40 | 34.75 | 64.94 | 45.27 | ||
| AM-DETR | - | 0.50 | 32.34 | 47.73 | 38.55 | |
| AM-DETR | 0.10 | 32.66 | 55.51 | 41.12 | ||
| RNN 39] | - | N/A | N/A | N/A | 50. |
mAP의 향상은 각각 29.00 및 23.11 포인트였습니다. 다음으로, 특징 추출기의 아키텍처 영향을 조사했습니다. VR과 CLAP(행 5와 6)을 비교했을 때, 성능은 비슷했으며 이는 AMR의 성능이 반드시 기존 오디오 검색의 성능과 일치하지는 않음을 나타냅니다. Window length. 오디오 인코더의 윈도우 길이에 대한 영향을 조사했으며, 그림 3의 왼쪽에서 볼 수 있듯이 더 짧은 윈도우 길이가 더 좋다는 것을 발견했습니다. 놀랍게도, 이 결과는 표 에 표시된 베이스라인의 결과와 대조됩니다. Amount of training data. 시뮬레이션된 훈련 데이터 양의 영향을 조사했습니다. 그림 3의 오른쪽에서 볼 수 있듯이, 데이터가 많을수록 성능이 향상되었으며, 데이터 양이 증가함에 따라 추가적인 개선이 기대됩니다. AMR as zero-shot SED. 섹션 II에서 설명했듯이 AMR 모델은 제로샷 SED로 볼 수 있으므로, 프레임 수준 분류로서의 SED 성능을 평가했습니다. 이벤트 레이블 이름과 프롬프트를 텍스트 쿼리로 사용하여 제로샷 SED를 수행했으며, SED 태스크의 기존 프레임 수준 메트릭을 기반으로 성능을 측정했습니다. AM-DETR과 CLAP 및 슬라이딩 윈도우를 단순히 결합한 모델(SED-CLAP이라고 함)을 평가했습니다. 임계값은 개발 세트로 F1 점수를 최대화하도록 조정했으며, 조정되지 않은 경우 임계값은 0.5로 설정되었습니다. 결과적으로 두 가지 중요한 결과를 발견했습니다. 첫째, AMR 모델은 제로샷 조건에도 불구하고 지도 학습 기반의 기존 SED 모델 F1 점수의 이상을 달성했습니다. 둘째, SED-CLAP과 비교할 때 AM-DETR은 임계값에 덜 민감하여 조정 노력을 줄입니다.
VI. Conclusion
우리는 새롭게 오디오 모멘트 검색이라는 과제를 제안했습니다. AMR 모델 훈련을 위해 Clotho-Moment라는 시뮬레이션 데이터셋을 제안했습니다. 제안된 방법은 실제 데이터를 사용한 평가에서 베이스라인을 크게 능가했습니다. 우리의 향후 연구에는 단일 쿼리에 관련된 여러 모멘트를 포함하는 더 큰 규모의 평가 데이터셋을 준비하는 것이 포함됩니다.
References
[1] A. S. Koepke, A.-M. Oncescu, J. F. Henriques, Z. Akata, and S. Albanie, "Audio retrieval with natural language queries: A benchmark study," IEEE Transactions on Multimedia, vol. 25, pp. 2675-2685, 2022. [2] K. Drossos, S. Lipping, and T. Virtanen, "Clotho: An audio captioning dataset," in Proc. ICASSP, 2020, pp. 736-740. [3] C. D. Kim, B. Kim, H. Lee, and G. Kim, "AudioCaps: Generating captions for audios in the wild," in Proc. NAACL-HLT, 2019, pp. 119132. [4] X. Mei, C. Meng, H. Liu, Q. Kong, T. Ko, C. Zhao, M. D. Plumbley, Y. Zou, and W. Wang, "Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research," IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024. [5] B. Elizalde, S. Deshmukh, and H. Wang, "Natural language supervision for general-purpose audio representations," in Proc. ICASSP, 2024, pp. 336-340. [6] Y. Wu, K. Chen, T. Zhang, Y. Hui, T. Berg-Kirkpatrick, and S. Dubnov, "Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation," in Proc. ICASSP, 2023, pp. 1-5. [7] A. Saeed, D. Grangier, and N. Zeghidour, "Contrastive learning of general-purpose audio representations," in Proc. ICASSP, 2021, pp. 3875-3879. [8] D. Niizumi, D. Takeuchi, Y. Ohishi, N. Harada, M. Yasuda, S. Tsubaki, and K. Imoto, "M2D-CLAP: Masked modeling duo meets clap for learning general-purpose audio-language representation," in Proc. Interspeech, 2024, pp. 57-61. [9] P. Primus, K. Koutini, and G. Widmer, "Advancing natural-language based audio retrieval with passt and large audio-caption data sets," in Proc. DCASE Workshop, September 2023, pp. 151-155. [10] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., "Learning transferable visual models from natural language supervision," in Proc. ICML. PMLR, 2021, pp. 8748-8763. [11] L. Anne Hendricks, O. Wang, E. Shechtman, J. Sivic, T. Darrell, and B. Russell, "Localizing moments in video with natural language," in Proc. ICCV, 2017, pp. 5803-5812. [12] J. Gao, C. Sun, Z. Yang, and R. Nevatia, "Tall: Temporal activity localization via language query," in Proc. ICCV, 2017, pp. 5267-5275. [13] K. Imoto, N. Tonami, Y. Koizumi, M. Yasuda, R. Yamanishi, and Y. Yamashita, "Sound event detection by multitask learning of sound events and scenes with soft scene labels," in Proc. ICASSP, 2020, pp. 621-625. [14] J. Lei, L. Yu, T. L. Berg, and M. Bansal, "TVR: A large-scale dataset for video-subtitle moment retrieval," in Proc. ECCV, 2020, pp. 447-463. [15] J. Lei, T. L. Berg, and M. Bansal, "Detecting moments and highlights in videos via natural language queries," in Proc. NeurIPS, vol. 34, 2021, pp. 11846-11858. [16] T. Komatsu, S. Watanabe, K. Miyazaki, and T. Hayashi, "Acoustic event detection with classifier chains," in Proc. Interspeech, 2021, pp. 601605. [17] W. Moon, S. Hyun, S. Park, D. Park, and J.-P. Heo, "Query-dependent video representation for moment retrieval and highlight detection," in Proc. CVPR, 2023, pp. 23 023-23033. [18] W. Moon, S. Hyun, S. Lee, and J.-P. Heo, "Correlation-guided querydependency calibration in video representation learning for temporal grounding," arXiv preprint arXiv:2311.08835, 2023. [19] Y. Xiao, Z. Luo, Y. Liu, Y. Ma, H. Bian, Y. Ji, Y. Yang, and X. Li, "Bridging the gap: A unified video comprehension framework for moment retrieval and highlight detection," in Proc. CVPR, 2024, pp. 18709-18719. [20] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, "End-to-end object detection with transformers," in Proc. ECCV, 2020, pp. 213-229. [21] E. Cakır, G. Parascandolo, T. Heittola, H. Huttunen, and T. Virtanen, "Convolutional recurrent neural networks for polyphonic sound event detection," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 6, pp. 1291-1303, 2017. [22] K. Miyazaki, T. Komatsu, T. Hayashi, S. Watanabe, T. Toda, and K. Takeda, "Convolution-augmented transformer for semi-supervised sound event detection," in Proc. DCASE Workshop, 2020, pp. 100-104. [23] T. Komatsu, K. Imoto, and M. Togami, "Scene-dependent acoustic event detection with scene conditioning and fake-scene-conditioned loss," in Proc. ICASSP, 2020, pp. 646-650. [24] A. Mesaros, T. Heittola, T. Virtanen, and M. D. Plumbley, "Sound event detection: A tutorial," IEEE Signal Processing Magazine, vol. 38, no. 5, pp. 67-83, 2021. [25] K. Li, Y. Song, L.-R. Dai, I. McLoughlin, X. Fang, and L. Liu, "AST-SED: An effective sound event detection method based on audio spectrogram transformer," in Proc. ICASSP, 2023, pp. 1-5. [26] N. Shao, X. Li, and X. Li, "Fine-tune the pretrained ATST model for sound event detection," in Proc. ICASSP, 2024, pp. 911-915. [27] X. Liu, H. Liu, Q. Kong, X. Mei, J. Zhao, Q. Huang, M. D. Plumbley, and W. Wang, "Separate what you describe: Language-queried audio source separation," in Proc. Interspeech, 2022, pp. 1801-1805. [28] C. Li, Y. Qian, Z. Chen, D. Wang, T. Yoshioka, S. Liu, Y. Qian, and M. Zeng, "Target sound extraction with variable cross-modality clues," in Proc. ICASSP, 2023, pp. 1-5. [29] S. Venkataramanan, M. N. Rizve, J. Carreira, Y. M. Asano, and Y. Avrithis, "Is imagenet worth 1 video? learning strong image encoders from 1 long unlabelled video," in Proc. ICLR, 2024. [30] Y. Fujita, N. Kanda, S. Horiguchi, K. Nagamatsu, and S. Watanabe, "End-to-end neural speaker diarization with permutation-free objectives," in Proc. Interspeech, 2019, pp. 4300-4304. [31] T. Geng, T. Wang, J. Duan, R. Cong, and F. Zheng, "Dense-localizing audio-visual events in untrimmed videos: A large-scale benchmark and baseline," in Proc. CVPR, 2023, pp. 22942-22951. [32] H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese, "Generalized intersection over union: A metric and a loss for bounding box regression," in Proc. CVPR, 2019, pp. 658-666. [33] T. Nishimura, S. Nakada, H. Munakata, and T. Komatsu, "Lighthouse: A user-friendly library for reproducible video moment retrieval and highlight detection," arXiv preprint arXiv:2408.02901, 2024. [34] S. Chen, H. Li, Q. Wang, Z. Zhao, M. Sun, X. Zhu, and J. Liu, "VAST: A vision-audio-subtitle-text omni-modality foundation model and dataset," in Proc. NeurIPS, 2024. [35] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, "RoBERTa: A robustly optimized bert pretraining approach," arXiv preprint arXiv:1907.11692, 2019. [36] H. Munakata, T. Nishimura, S. Nakada, and T. Komatsu, "Training strategy of massive text-to-audio models and gpt-based query-augmentation," in DCASE Challenge, Technical Report, 2024. [37] I. Loshchilov, "Decoupled weight decay regularization," arXiv preprint arXiv:1711.05101, 2017. [38] A. Mesaros, T. Heittola, and T. Virtanen, "TUT database for acoustic scene classification and sound event detection," in Proc. EUSIPCO, Budapest, Hungary, 2016. [39] K. Drossos, S. Gharib, P. Magron, and T. Virtanen, "Language modelling for sound event detection with teacher forcing and scheduled sampling," in Proc. DCASE Workshop, New York University, NY, USA, October 2019, pp. 59-63.